分布式日志系统-ELK
ELK即Elasticsearch、Logstash、Kibana,组合起来可以搭建线上日志系统,后期出现的filebeat(beats中的一种)可以用来替代logstash的数据收集功能,比较轻量级)。市面上也被称为Elastic Stack。
ELK中各个服务的作用
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
Logstash是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。Logstash能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用Grok从非结构化数据中派生出结构,从IP地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
Elasticsearch是Elastic Stack核心的分布式搜索和分析引擎,是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。Elasticsearch为所有类型的数据提供近乎实时的搜索和分析。无论您是结构化文本还是非结构化文本,数字数据或地理空间数据,Elasticsearch都能以支持快速搜索的方式有效地对其进行存储和索引。
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。并且可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以汇总、分析和搜索重要数据日志。还可以让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态
业务场景
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
往往单台机器的日志我们使用grep、awk等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
概括:一个收集各个系统日志集中起来,分析处理的系统,用于给运维人员排查问题
系统架构
| 方案编号 | 核心组件 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 2.1 | Beats+Elasticsearch+Kibana | 测试/小规模日志收集 | - 部署简单、上线快 - 资源消耗低 - Filebeat 自带 module,可快速解析常见日志并附带预建仪表板 | - 无持久化缓冲,抗突发流量能力弱 - 日志清洗和路由能力有限 - 不适合高可靠性生产环境 |
| 2.2 | Beats+Logstash+Elasticsearch+Kibana | 中型生产环境 | - Logstash 磁盘自适应缓冲,缓解背压 - 支持多源抽取、多目的地输出 - 持久队列+确认机制,保证至少一次投递 - 全链路加密与认证 | - 架构复杂度和运维成本提升 - Logstash 可能成为性能瓶颈,需要调优和横向扩展 - 配置和监控更繁琐 |
| 2.3 | Beats+缓存/消息队列(Kafka/Redis/RabbitMQ)+Logstash+Elasticsearch+Kibana | 大规模、高并发、强可靠性场景 | - 队列解耦生产与消费,降低对源端和 ES 的冲击 - 缓冲保护,网络或节点故障时保证不丢数据 - 中央化处理(格式化、清洗)易于维护 | - 增加中间件运维和监控开销 - 额外的消息延迟 - 架构最复杂,需要更多资源投入 |
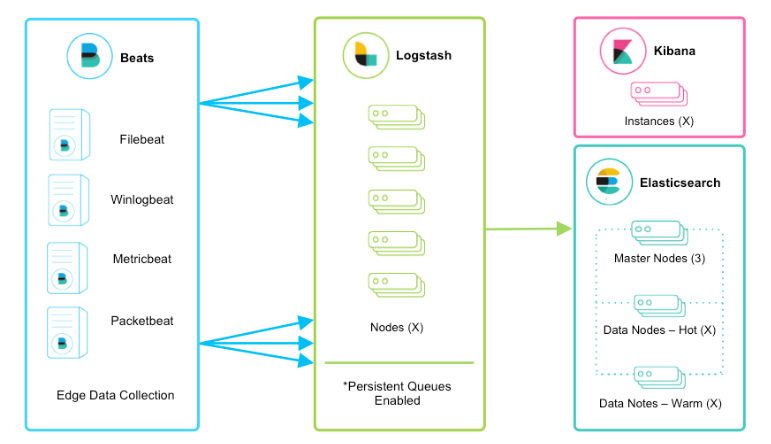
该框架是在上面的框架的基础上引入了logstash,引入logstash带来的好处如下:
- 通Logstash具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻背压
- 从其他数据源(例如数据库,S3或消息传递队列)中提取
- 将数据发送到多个目的地,例如S3,HDFS或写入文件
- 使用条件数据流逻辑组成更复杂的处理管道
filebeat结合logstash带来的优势:
1、水平可扩展性,高可用性和可变负载处理:filebeat和logstash可以实现节点之间的负载均衡,多个logstash可以实现logstash的高可用
2、消息持久性与至少一次交付保证:使用Filebeat或Winlogbeat进行日志收集时,可以保证至少一次交付。从Filebeat或Winlogbeat到Logstash以及从Logstash到Elasticsearch的两种通信协议都是同步的,并且支持确认。Logstash持久队列提供跨节点故障的保护。对于Logstash中的磁盘级弹性,确保磁盘冗余非常重要。
3、具有身份验证和有线加密的端到端安全传输:从Beats到Logstash以及从 Logstash到Elasticsearch的传输都可以使用加密方式传递 。与Elasticsearch进行通讯时,有很多安全选项,包括基本身份验证,TLS,PKI,LDAP,AD和其他自定义领域
当然在该框架的基础上还可以引入其他的输入数据的方式:比如:TCP,UDP和HTTP协议是将数据输入Logstash的常用方法(如下图所示):
部署
创建一个存放logstash配置的目录并上传配置文件
logstash-springboot.conf文件内容
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
output {
elasticsearch {
hosts => "es:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
}
}
创建配置文件存放目录并上传配置文件到该目录
mkdir /mydata/logstash
使用docker-compose.yml脚本启动ELK服务
version: '3'
services:
elasticsearch:
image: elasticsearch:6.4.0
container_name: elasticsearch
environment:
- "cluster.name=elasticsearch" #设置集群名称为elasticsearch
- "discovery.type=single-node" #以单一节点模式启动
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" #设置使用jvm内存大小
volumes:
- /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins #插件文件挂载
- /mydata/elasticsearch/data:/usr/share/elasticsearch/data #数据文件挂载
ports:
- 9200:9200
- 9300:9300
kibana:
image: kibana:6.4.0
container_name: kibana
links:
- elasticsearch:es #可以用es这个域名访问elasticsearch服务
depends_on:
- elasticsearch #kibana在elasticsearch启动之后再启动
environment:
- "elasticsearch.hosts=http://es:9200" #设置访问elasticsearch的地址
ports:
- 5601:5601
logstash:
image: logstash:6.4.0
container_name: logstash
volumes:
- /mydata/logstash/logstash-springboot.conf:/usr/share/logstash/pipeline/logstash.conf #挂载logstash的配置文件
depends_on:
- elasticsearch #kibana在elasticsearch启动之后再启动
links:
- elasticsearch:es #可以用es这个域名访问elasticsearch服务
ports:
- 4560:4560
SpringBoot应用集成Logstash
<!--集成logstash-->
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.3</version>
</dependency>
添加配置文件logback-spring.xml让logback的日志输出到logstash
注意appender节点下的destination需要改成你自己的logstash服务地址,比如我的是:192.168.3.101:4560。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<!--应用名称-->
<property name="APP_NAME" value="mall-admin"/>
<!--日志文件保存路径-->
<property name="LOG_FILE_PATH" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/logs}"/>
<contextName>${APP_NAME}</contextName>
<!--每天记录日志到文件appender-->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE_PATH}/${APP_NAME}-%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>192.168.3.101:4560</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
总结
搭建了ELK日志收集系统之后,我们如果要查看SpringBoot应用的日志信息,就不需要查看日志文件了,直接在Kibana中查看即可。